- variableThe name of the variable that this object applies to
C++ Type:AuxVariableName
Controllable:No
Description:The name of the variable that this object applies to
HardwareIDAux
Creates a field showing the assignment of partitions to physical nodes in the cluster.
Description
One of the main purposes of this object is to aid in the diagnostic of mesh partitioners. One metric to look at for mesh partitioners is how well they keep down inter-node (compute node) communication. HardwareIDAux allows you to visually see the mapping of elements to compute nodes in your job.
This is particularly interesting in the case of the PetscExternalPartitioner which has the capability to do "hierarchical" partitioning. Hierarchical partitioning makes it possible to partition over compute-nodes first... then within compute nodes, in order to better respect the physical topology of the compute cluster.
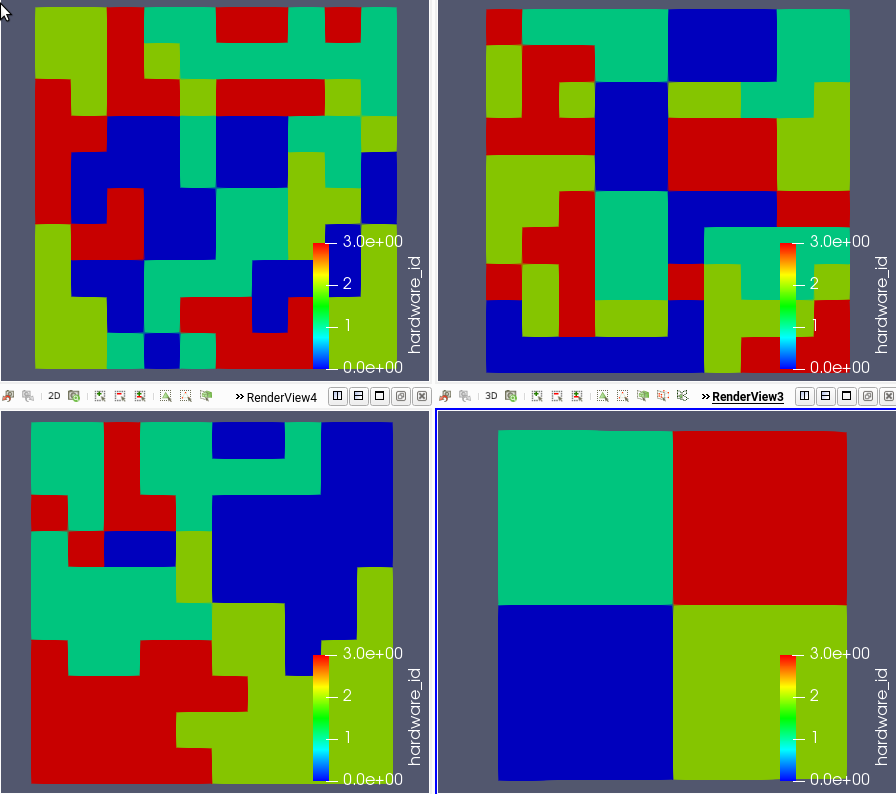
One important aspect of that is that how you launch your parallel job can matter quite a bit to partitioning. In-general, it's better for partitioners if all of the ranks of your job are contiguously assigned to each compute node. Here are four different ways, and the outcome using HardwareIDAux, to launch a job using a 100x100 generated mesh on 16 processes and 4 ndoes with two different partitioner...
Top left (METIS):
mpiexec -n 16 -host lemhi0002,lemhi0003,lemhi0004,lemhi0005 ../../../moose_test-opt -i hardware_id_aux.i
Top right (Hierarchic):
mpiexec -n 16 -host lemhi0002,lemhi0003,lemhi0004,lemhi0005 ../../../moose_test-opt -i hardware_id_aux.i -mat_partitioning_hierarchical_nfineparts 4
Bottom left (METIS):
mpiexec -n 16 -host lemhi0002,lemhi0003,lemhi0004,lemhi0005 -ppn 4 ../../../moose_test-opt -i hardware_id_aux.i
Bottom right (Hierarchic):
mpiexec -n 16 -host lemhi0002,lemhi0003,lemhi0004,lemhi0005 -ppn 4 ../../../moose_test-opt -i hardware_id_aux.i -mat_partitioning_hierarchical_nfineparts 4
It should be immediately apparent that the bottom right partitioning is best (will reduce the amount of inter-node communication). That result was achieved by using hierarchical partitioning and using -ppn 4 to tell mpiexec to put 4 processes on each compute node... which will cause those four processes to be contiguous on each node. The top two examples, which omit the -ppn option, end up getting "striped" mpi processes (one process is placed on each node and then it wraps around) causing a jumbly mess of partitioning which will increase the communication cost for the job (and decrease scalability).
Input Parameters
- blockThe list of blocks (ids or names) that this object will be applied
C++ Type:std::vector<SubdomainName>
Controllable:No
Description:The list of blocks (ids or names) that this object will be applied
- boundaryThe list of boundaries (ids or names) from the mesh where this object applies
C++ Type:std::vector<BoundaryName>
Controllable:No
Description:The list of boundaries (ids or names) from the mesh where this object applies
- check_boundary_restrictedTrueWhether to check for multiple element sides on the boundary in the case of a boundary restricted, element aux variable. Setting this to false will allow contribution to a single element's elemental value(s) from multiple boundary sides on the same element (example: when the restricted boundary exists on two or more sides of an element, such as at a corner of a mesh
Default:True
C++ Type:bool
Controllable:No
Description:Whether to check for multiple element sides on the boundary in the case of a boundary restricted, element aux variable. Setting this to false will allow contribution to a single element's elemental value(s) from multiple boundary sides on the same element (example: when the restricted boundary exists on two or more sides of an element, such as at a corner of a mesh
- execute_onLINEAR TIMESTEP_ENDThe list of flag(s) indicating when this object should be executed, the available options include NONE, INITIAL, LINEAR, NONLINEAR, TIMESTEP_END, TIMESTEP_BEGIN, MULTIAPP_FIXED_POINT_END, MULTIAPP_FIXED_POINT_BEGIN, FINAL, CUSTOM, ALWAYS, PRE_DISPLACE.
Default:LINEAR TIMESTEP_END
C++ Type:ExecFlagEnum
Controllable:No
Description:The list of flag(s) indicating when this object should be executed, the available options include NONE, INITIAL, LINEAR, NONLINEAR, TIMESTEP_END, TIMESTEP_BEGIN, MULTIAPP_FIXED_POINT_END, MULTIAPP_FIXED_POINT_BEGIN, FINAL, CUSTOM, ALWAYS, PRE_DISPLACE.
- prop_getter_suffixAn optional suffix parameter that can be appended to any attempt to retrieve/get material properties. The suffix will be prepended with a '_' character.
C++ Type:MaterialPropertyName
Controllable:No
Description:An optional suffix parameter that can be appended to any attempt to retrieve/get material properties. The suffix will be prepended with a '_' character.
Optional Parameters
- control_tagsAdds user-defined labels for accessing object parameters via control logic.
C++ Type:std::vector<std::string>
Controllable:No
Description:Adds user-defined labels for accessing object parameters via control logic.
- enableTrueSet the enabled status of the MooseObject.
Default:True
C++ Type:bool
Controllable:Yes
Description:Set the enabled status of the MooseObject.
- seed0The seed for the master random number generator
Default:0
C++ Type:unsigned int
Controllable:No
Description:The seed for the master random number generator
- use_displaced_meshFalseWhether or not this object should use the displaced mesh for computation. Note that in the case this is true but no displacements are provided in the Mesh block the undisplaced mesh will still be used.
Default:False
C++ Type:bool
Controllable:No
Description:Whether or not this object should use the displaced mesh for computation. Note that in the case this is true but no displacements are provided in the Mesh block the undisplaced mesh will still be used.